
EdgeRunner 2: A New State of the Art for Military LLMs on the Edge
Today, we are introducing EdgeRunner 2, a suite of LLMs that set a new State of the Art (SOTA) for military LLMs at the edge.
Beginning with the American-made open-weight models, we apply a wide range of training techniques, including supervised fine tuning, distillation, and reinforcement learning. We teach our models about military doctrine and operations using our ever-growing training corpus composed of 5B unsupervised tokens from official sources, an additional 190B tokens from military-relevant sources, and 3M high-quality Q&A pairs.
All training data are unclassified, with a mixture of public and private data. Training is guided by an extensive military benchmarking suite derived from contributions from military subject matter experts. The resulting models are best-in-class for military use cases at the edge.
Our goal is to help the warfighter make better decisions, acquire knowledge, and execute the mission, even in the harshest and most austere environments. Our models are efficient enough to run without internet connectivity on edge devices while still achieving comparable accuracy to cloud and frontier models on a diverse array of military tasks.
Key Results
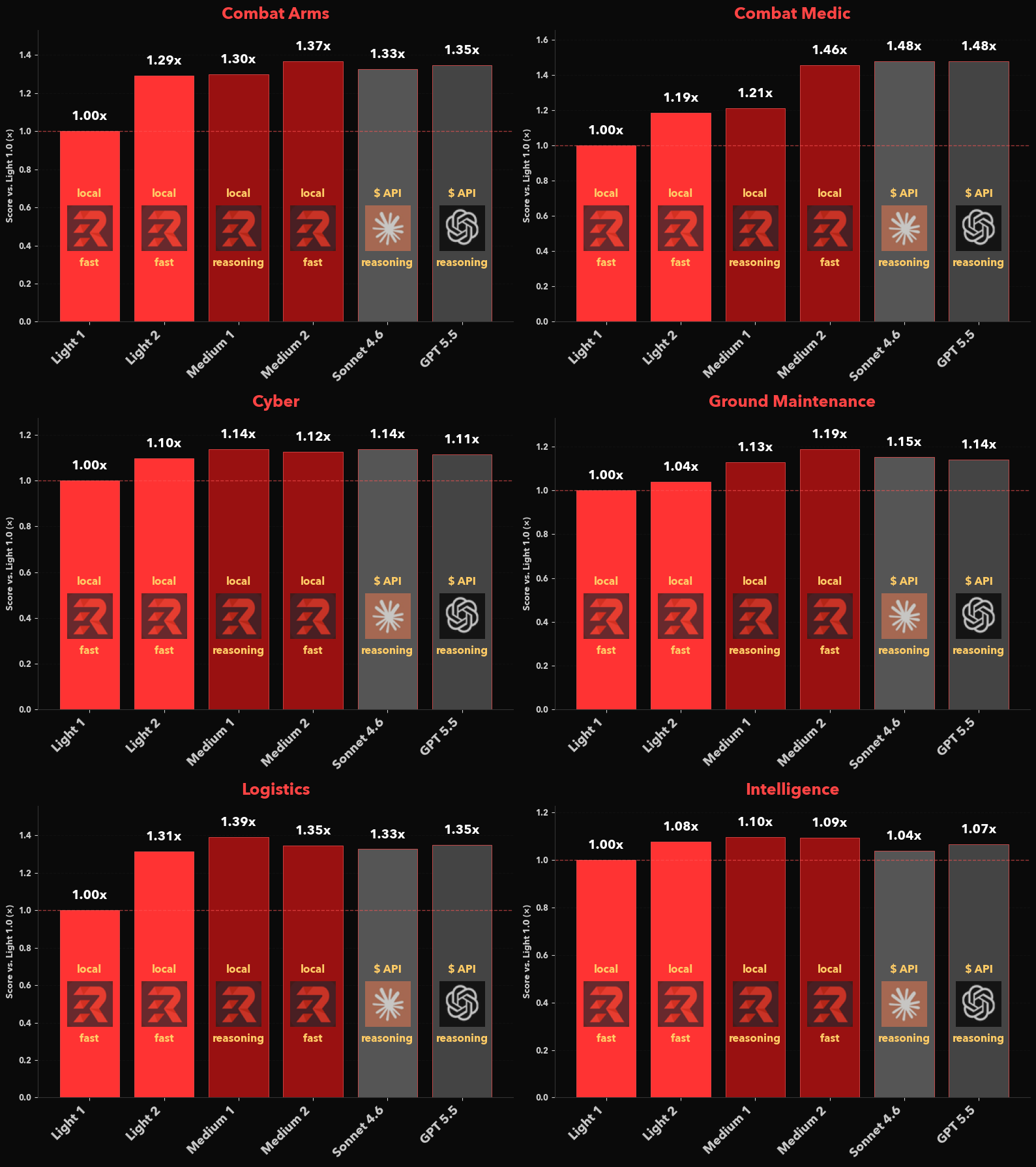
EdgeRunner 2 models are substantially improved versus both EdgeRunner 1 and the world’s best frontier models. Our Light model is designed for commodity laptops and certain smartphones. It runs on hardware with 8+ GB of VRAM. Our Medium model, which is designed for more powerful workstation-style laptops, runs with as little as 16 GB of VRAM. Below we show select benchmarking results on six test sets, including combat arms, combat medicine, cyber operations, ground vehicle maintenance, logistics, and field intelligence. In each case the output from the assessed model is compared to the ground truth using a powerful judge model. Our model evaluation tools are described in a previous article, Military AI Benchmarking: How We Evaluate LLMs for the Warfighter.
We observe the following:
- EdgeRunner Medium 2 continues to match or exceed frontier model performance.
- EdgeRunner Medium 2 is either improved or comparable to Medium 1, despite being a “fast”, non-reasoning model, whereas Medium 1 was a reasoning model.
- EdgeRunner Light 2 is a dramatic improvement from EdgeRunner Light 1. Light 2 is near parity with Medium 1, even rivaling Medium 2 in some cases.
EdgeRunner models save money. The military evaluations performed for this study, which consisted of 22 military benchmarks and two system prompts, cost us $442 to run with GPT 5.5. EdgeRunner models, on the other hand, run on one’s own hardware with zero subscription or token costs. Moreover, because Light 2 and Medium 2 are non-reasoning models, they produce fewer tokens, which makes the time to first answer token nearly imperceptible in typical use, as shown in Figure 3.
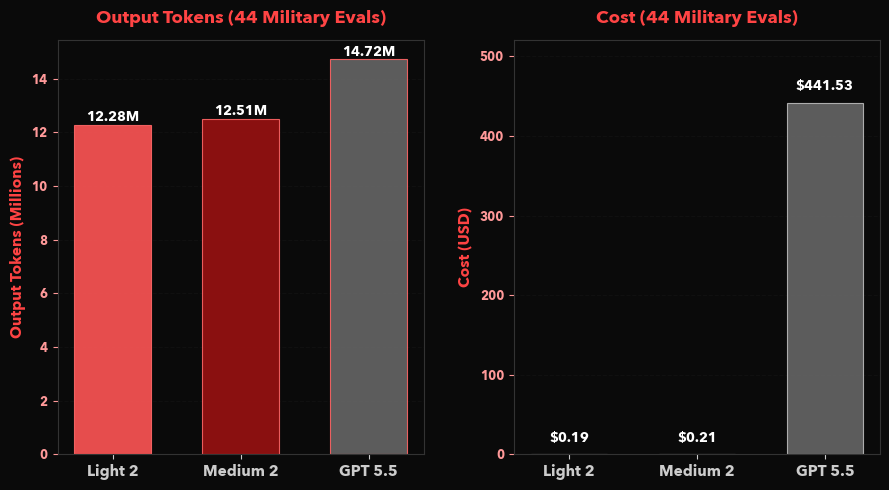
Because Light 2 and Medium 2 forego reasoning, the time to first answer token is nearly imperceptible:
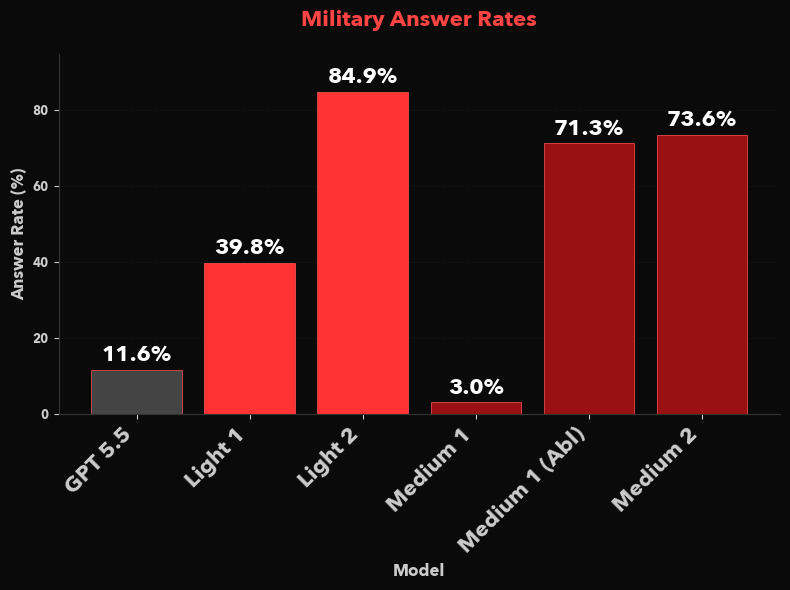
We present the answer rates on mil-deflect-gold-alpha, our dataset created by special forces operators to assess an LLM’s propensity for refusing to answer legitimate military queries. The dataset and the methodology are described further in our paper. Figure 4 shows substantial improvements in answer rate for Light 2. The improvement between Medium 1 and 2 is substantial, and the abliterated [1, 2] version of Medium 1 is also presented for comparison. Both Light 2 and Medium 2 substantially outperform frontier models like GPT 5.5. We continue to actively invest in the reduction of military refusals, and we expect to release a minor update to the EdgeRunner 2 models with even higher answer rates in the near future.
Training
EdgeRunner models are built using a range of training techniques, including the following:
- Supervised Fine Tuning (SFT) uses Question and Answer (Q&A) pairs to teach the model how to interact with military users, as well as how to ground its responses in correct military doctrine. We have curated over 3M high-quality Q&A pairs, with more being made each month.
- Pretraining and Continued Pretraining leverage unstructured data, including 5B unsupervised tokens from official sources and an additional 190B tokens from military-relevant sources, to inject knowledge using next-token prediction.
- Off-Policy Distillation can use either unstructured data or structured data like Q&A pairs. The data are fed to both the student model and a more powerful teacher model. In normal training the student only learns the chosen word in the ground truth. With distillation, the student can also learn to represent the distribution of word probabilities at each position in the sequence, leading to faster training convergence and higher final benchmark scores.
- On-Policy Distillation also uses a teacher model, but the setup is different. Whereas with off-policy distillation full ground truth is required (EX: the question and answer), with on-policy distillation, only a prompt, the input, is used. The prompt is fed to the student, the student generates candidate answers, and the teacher grades each answer, including the token-level probability distributions.
- Direct Preference Optimization (DPO) and Reinforcement Learning from Human Feedback (RLHF) rely on preference pairs, in which a human or a model assesses two or more answers to one question. These methods are effective at teaching the model the long tail of subtleties in the English language, particularly for unique domains like the military lexicon.
Besides these existing training methods, we have developed a technique called EviDence GuidEd On-Policy Distillation (EDGE-OPD), which allows us to inject knowledge during on-policy distillation, which is valuable for the case in which neither the student nor the teacher has seen the new knowledge. We will release a paper describing this technique soon.
Get Started!
Our new models are available to the military and defense professionals through our DoW trial program, here.
EdgeRunner Research | research@edgerunnerai.com | 21 May 2026