
EdgeRunner Achieves GPT-5 Level Performance in Key Military Tasks While Running Locally On-Device
Two years ago many believed GPT-4–level performance on a commodity device was impossible due to compute, memory, and power constraints inherent to edge hardware. EdgeRunner AI overcame those limits—achieving GPT-5–class capability entirely on-device—and is the first in the world to operationalize it for the military and for Denied, Degraded, Intermittent, and Limited (DDIL) use cases.
We are excited to introduce EdgeRunner 20B, a new model developed by EdgeRunner AI that matches GPT-5 task performance on four military test sets while running completely air-gapped on an edge device. Full results are available in our paper on arXiv. These results corroborate our thesis that deep military customization allows us to shrink foundation model sizes from hundreds of billions or trillions of parameters all the way down to 20 billion quantized parameters or fewer without sacrificing task performance on capabilities that are important to the warfighter.
Introducing Four New Military Test Sets
A key component of our modeling strategy is the creation of high-quality military test sets vetted by experienced military professionals. Without good test data, our industry is shooting in the dark toward targets we cannot see. At EdgeRunner we consider three classes of test sets, being (a) gold test sets, which are created by one or more military Subject Matter Experts (SMEs) from scratch without any AI assistance, (b) silver test sets, which are vetted by SMEs but for which some level of AI assistance was used, including example creation, filtering, or creation, and (c) bronze test sets, which are created by our research team for development purposes but are not vetted by a military SME.
In this work we introduce four new test sets, including:
- combat-arms - a 180-example silver dataset covering the combat arms career field with a focus on the infantry,
- combat-medic - a 446-example silver dataset covering the combat medic career field,
- cyber - a 142-example gold cybersecurity and operations dataset covering (a) compliance, (b) training, (c) incident response, (d) mission planning, (e) security procedures, (f) threat intelligence, and (g) tooling.
- mil-bench-5k - a 5,000-example silver dataset covering a wide range of military topics sourced from official military publications.
The cyber dataset was created by a US Army cyber operations expert from scratch, and the remaining three datasets were vetted by three US Army officers with combined experience of over 45 years, including 20 years of special missions experience.
Training Methods
We leveraged EdgeRunner’s Supervised Fine Tuning (SFT) data creation pipeline to generate a high-quality training dataset of 1.6M training examples. In the first stage of our pipeline, we use an LLM to summarize each document across our large corpus of military documentation. This summary is used by another LLM in the second stage of the pipeline, in which question-answer pairs are generated chunkwise from our documents using each document’s summary as context. In the final stage, a different LLM evaluates the quality of the generated question-answer pairs, passing those of high quality, sending medium quality ones back for rework, and discarding low quality pairs.
Training runs were conducted using gpt-oss-20b as the base model, We experimented with various training libraries and techniques, including axolotl, TRL, and quantization-aware training with TensorRT Model Optimizer; varying learning rates and batch sizes; using synthetic reasoning data generated by gpt-oss-120b; and with varying chat templates. In our paper we provide key takeaways from our experimentation for effective fine tuning of gpt-oss-20b.
Results
We compare our fine-tuned model to GPT-5, and we find that, barring a few outliers in both directions, our model can match GPT-5 task performance on our military tasks, all while being small enough to run on a user’s local device.
Recent GPT models employ a user-configurable reasoning effort setting that determines how long the model will think before yielding the final answer. Figure 1 below shows the relative error rate versus the medium reasoning effort setting with GPT-5. Because our test sets are relatively small, it’s important also to examine the p-values, which are a measure of statistical similarity. Only in cases where the p-value is less than 0.05 do we consider the difference between GPT-5 and EdgeRunner 20B to be statistically significant. The p-value results are given in Table 1, below.
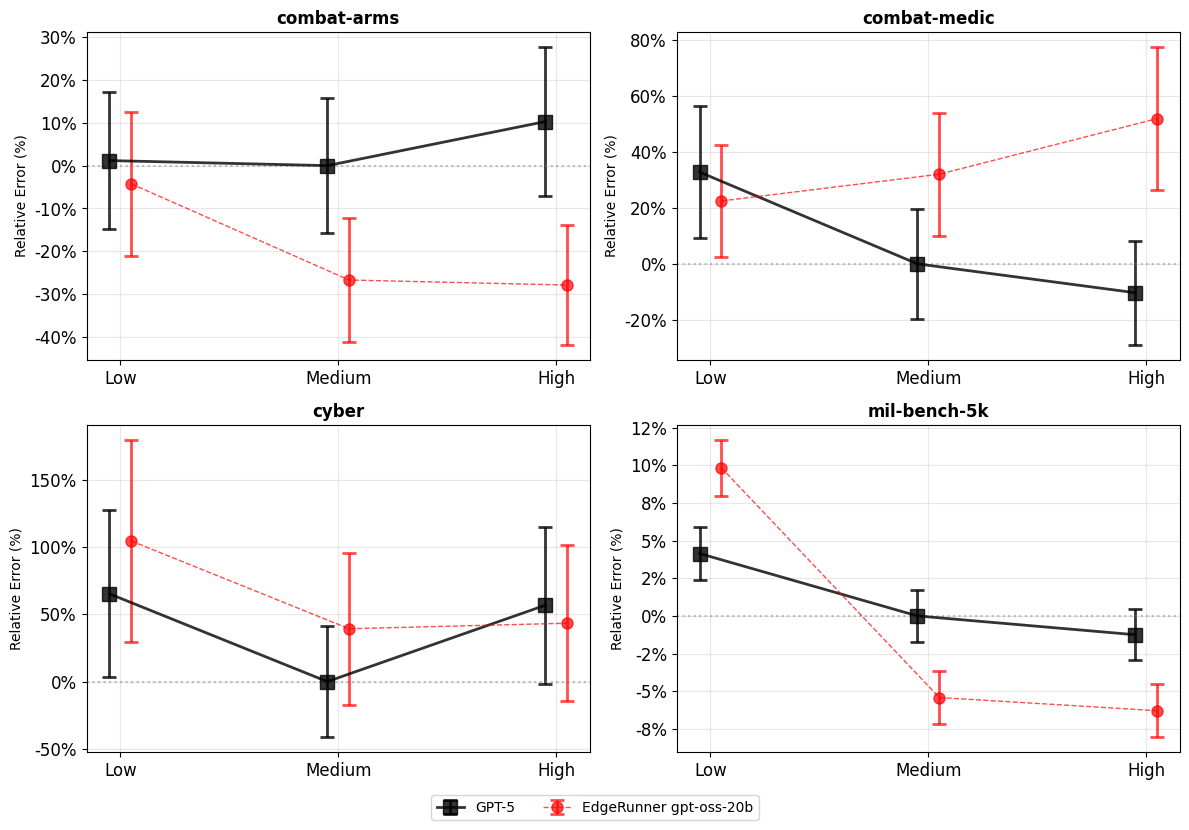
Figure 1: EdgeRunner 20B and GPT-5 error rates at low, medium, and high reasoning effort relative to the medium reasoning effort setting of GPT-5. Lower is better (less error).

Table 1: P-values for EdgeRunner 20B versus GPT-5 across four military test sets and three reasoning effort settings. Only if the p-value is lower than 0.05 is the difference between EdgeRunner 20B and GPT-5 statistically significant. “Win” means that EdgeRunner 20B had fewer errors than GPT-5, whereas “loss” means that GPT-5 had fewer errors than EdgeRunner 20B.
Examining these results, we see three wins and two losses for EdgeRunner 20B versus GPT-5. In seven out of twelve cases, the models tie. In net, we consider the two models’ performance on these four tasks as being comparable.
Looking Ahead
We are currently working on a host of additional test sets, including gold test sets for combat medicine, tactical combat arms, operational combat arms, vehicle maintenance, and aircraft maintenance. Over time we will develop a robust suite of evaluations and an associated leaderboard. Additionally, we are preparing a series of tests and metrics for measuring the rates of request deflection and resolution, as well as novel approaches for improving model performance based on these criteria.
Our model experimentation spans a wide range of model sizes and end user stories. We build everything from light models that can run on mobile devices to medium models for laptops, such as EdgeRunner 20B, to heavy models that run on dedicated servers. A series of new innovations are in the works, and we look forward to sharing more with you soon.
Whether in the field, at sea, in the air, or in space, we bring the warfighter state-of-the-art AI technology that always works and is always ready, even if the network is down or the fog of war sets in. Besides their resiliency, local AI models are the most secure system architecture possible. Moreover, local processing can lower costs substantially over time, which translates to higher rates of technology deployment and a greater level of asymmetric advantage for our troops.
Read our full paper here: https://arxiv.org/abs/2510.26550v1