
No Cloud, No Problem – EdgeRunner Delivers the Fastest On-Device AI Behind Enemy Lines
In Denied, Disrupted, Intermittent, and Limited (DDIL) environments, the warfighter cannot rely on AI solutions that require constant cloud connectivity. At EdgeRunner, we’ve architected our platform from the beginning to run completely air-gapped on-device, bringing the power of our military-specific LLMs directly to your workstation, laptop, or smartphone without relying on network connectivity.
Core to our product is our inference backend, which powers the world’s fastest on-device military-specific AI agents. In this blog post, we provide an overview of the technical aspects of the EdgeRunner backend, using other industry software, including Ollama, as a point of comparison.
In subsequent blog posts, we’ll discuss the importance of military-specific LLMs and how the warfighter is using our software in the field today.
1. Direct Llama.cpp Integration
EdgeRunner utilizes a modular approach to software development, with our runners talking to the overall backend application through a unified interface. This allows us to test, develop and support inference engines with ease.
Instead of relying on 3rd party microservices, our runner architecture also allows us to easily employ direct integration with llama.cpp, which unlocks optimized inference for many common devices. This direct integration also allows the user to exert granular control over the behavior of the entire inference stack, ensuring system resources such as memory are only utilized as needed, and released immediately upon closure.
This direct integration and flexible runner strategy also gives us the ability to scale inference for different deployment scenarios, whether if it’s for hot-swapping LoRAs, support for multi-model multi-user serving, or running multiple models on multiple stacks under the hood, without requiring the user to install any other pieces of software, do any meddling with command line, simply install EdgeRunner and you’ll be off to the races.
2. OpenAI API Support
While EdgeRunner’s overall application employs several augments to the API to enable more user functionality (such as expanded file collections, easy references to image/files, tool use & more), the overall API spec still supports the OpenAI API, which enables 3rd party applications to easily use EdgeRunner as an easy inference backend, with automatic model loading/swapping & memory management.
This dedication to making things simple for the community drives our core engineering decisions, and ensures that any custom software will be able to integrate with our applications without any major modifications.
3. Model Support & Performance
The modular approach to runners also gives us the flexibility to utilize whatever techniques that are required to deliver maximum performance to our end users.
Compared to Ollama, we achieve >210% tok/s in prompt processing (for 4k token sequences), and >450% token generation (for 1k token sequences), tested through both our and Ollama’s API interfaces, for gpt-oss 20b at original precision.
We also support a wide array of open-source models without any proprietary blockers for integration, for instance EdgeRunner works with any community-supplied GGUF models, OpenVINO models, and more!
EdgeRunner also automatically detects and self-configures for best performance on your target device, no user intervention required.
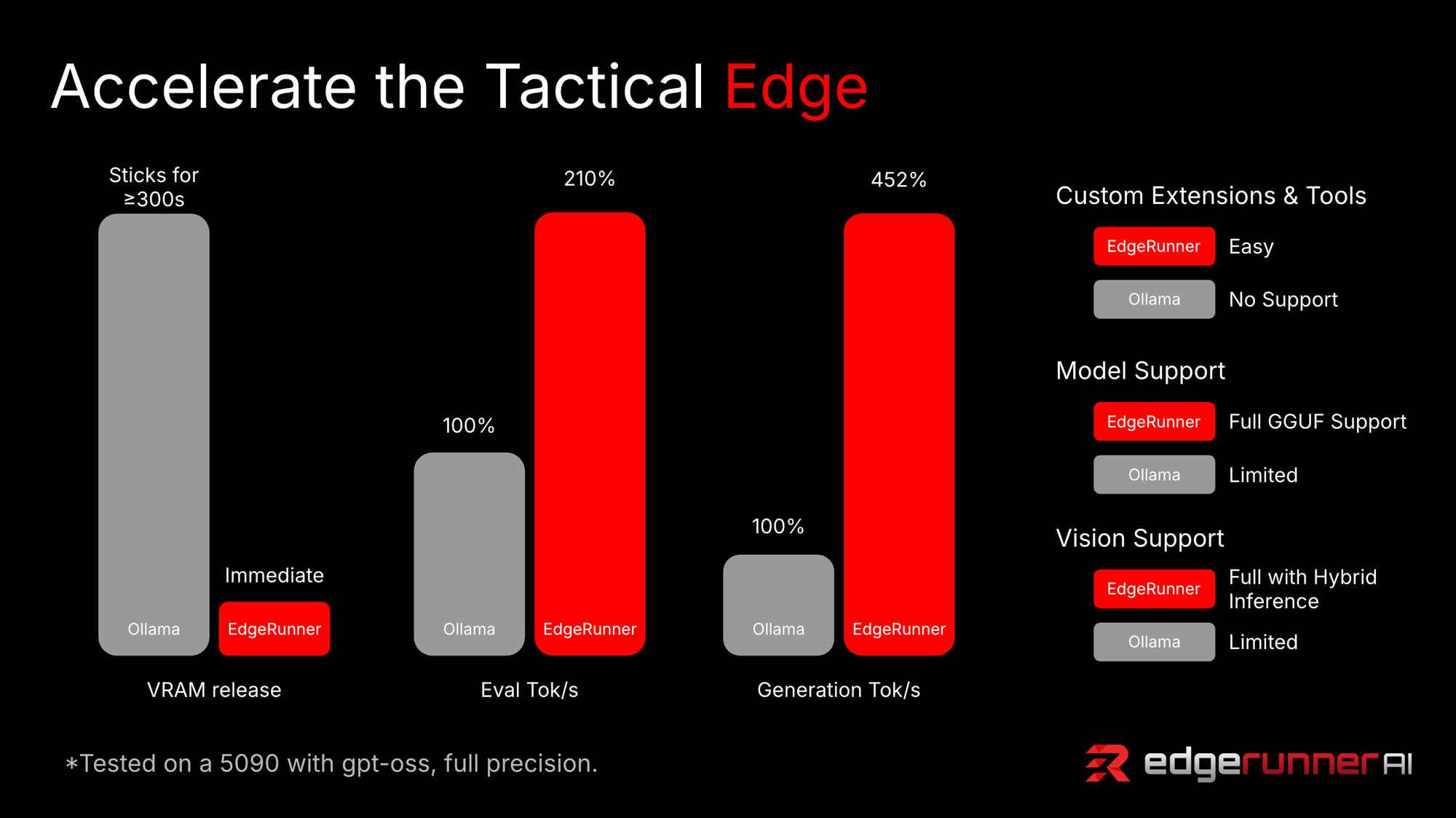
4. Vision, Tools and Files
Instead of relying on 3rd party software for tool use support, the EdgeRunner frontend + backend application allows you to either integrate MCP or easily define your own local tools through python-based extensions, when function calling is enabled, EdgeRunner dynamically loads all available tools and runs them when required.
We also have direct VLM support with our chat interface recreating the simple, intuitive chat experience you may have with images in other platforms, intelligently routing uploads, preserving locations in chat, and dynamic previews, all locally.
We also have integrated vector store and file ingestion capabilities, optimized to work with arbitrary engines, on arbitrary devices, even encrypted if you would like it to be! File collections are fast & easy, as simple as drag & drop, and our (again, modular!) storage systems allow more advanced deployments to make conscious tradeoffs for speed & resource utilization.
5. EdgeRunner Compression
Our internal GGUF-based compression/quantization strategies allow for models to be reduced to <30% of their original size, while preserving ~98.5% of the original quality, compared to ~91% with naive techniques, tested on open source benchmarks such as TruthfulQA. This allows us to deploy models onto relatively low-power edge devices, such as low-spec laptops without dedicated graphics, or mobile devices such as Android/Apple phones.
This compression strategy also nets us a >260% boost in generation speeds, far surpassing that of our competitors at equal size/quality. Our targeted optimization strategies also net us ~0% degradation over our fine-tuned models, opposed to a simple strategy which yields ~3% loss in answering capability.