
PRC vs. Western Open-Source AI Models: What It Means for Agentic AI
Prepared for: U.S. Congressional Staff
Prepared by: EdgeRunner AI
Date: 28 April 2026
Executive Summary
The United States maintains a lead in closed-frontier models (GPT-5, Claude 4.6, Gemini 3.0 Pro, Grok 4.2), but China now dominates the open-weight tier—the models most U.S. builders, sovereign-edge deployments, and agentic systems run.
Four key findings:
- 19 of the top 20 open-weight models are Chinese. The leading U.S. open model (Gemma 4, 31B) ranks #19. Western labs have largely stopped releasing open models above ~120B parameters; Chinese labs release 200B–1.6T models monthly.
- Chinese open weights have reached or surpassed U.S. frontier performance on agentic benchmarks. Qwen 3.6 matches Claude Sonnet/Opus 4.5-level general capability. On Claw-Eval, Xiaomi’s open-weight MiMo V2.5 Pro ranks above GPT-5.4, Meta’s Muse Spark, and Gemini 3.1 Pro.
- The agentic economy is voting Chinese. Moonshot Kimi is #1 on OpenRouter; Cursor’s flagship coding model is a tuned Kimi K2.5; Nvidia’s Nemotron builds on Qwen 3. Real-world agentic workloads run at ~$0 marginal cost on Chinese open weights versus thousands on closed APIs.
- U.S. open weights are becoming a supply-chain vulnerability. Several U.S.-trained models now exhibit Chinese model “identity contamination” in outputs, indicating Chinese data has entered U.S. pre-training distributions.
Bottom line: The U.S. is not losing the overall AI race, but it is losing the open-weight tier that determines control of sovereign edge, contested-environment, and agentic-builder AI. This gap has immediate national-security consequences for military, intelligence, and disconnected operations.
1. The Race Has Split into Two Tiers

Pace (last 60 days): China released Minimax M2.5/2.7, Kimi 2.5/2.6, Qwen 3.5/3.6, GLM 5.1, DeepSeek v4, Xiaomi MiMo (3 variants), and more. U.S. releases: Google Gemma 4 and IBM Granite 4.1 only.
Chinese labs lead in parameter efficiency, long-context architectures (linear attention, n-gram caches, multi-token prediction), and auxiliary tools (OCR, vision, video). Most equivalent U.S. architectural R&D is now closed source.

2. Agentic AI: Operational Reality
Agentic systems—autonomous task completion, multi-step reasoning, tool use, and long-context operation—are the decisive use case.
No one has “won” yet. Remote Labor Index ~4%; most models score below 50% on Berkeley Function Calling Leaderboard v4.
U.S. closed lead is being pierced on agentic benchmarks. Xiaomi MiMo V2.5 Pro (open-weight) now tops Claw-Eval, ahead of GPT-5.4 and other U.S. frontier models.
Real-world usage confirms the shift. On OpenRouter: #1 model is Moonshot Kimi (Chinese); top three providers by volume are all Chinese (StepFun alone served 3.5T tokens). Cursor’s Composer 2 (world’s leading coding app) uses tuned Kimi K2.5.
Cost reality drives adoption. One EdgeRunner AI engineer runs a full agentic workload (~2 gigatokens/month) on consumer GPUs at $0 cost using Chinese open weight models. The Equivalent usage would cost $6,000/month on Claude Sonnet 4.5 for equivalent capability. Agentic workflows drive dramatically higher token usage which alters the cost/benefit baseline.
Ecosystem advantage: China is agentic-first. It ships open multi-agent frameworks (Manus/OpenManus), inference backends, curated agentic datasets, and post-training optimized for autonomous operation—layers the U.S. has not matched at open-source scale.


3. Supply-Chain and Provenance Risks
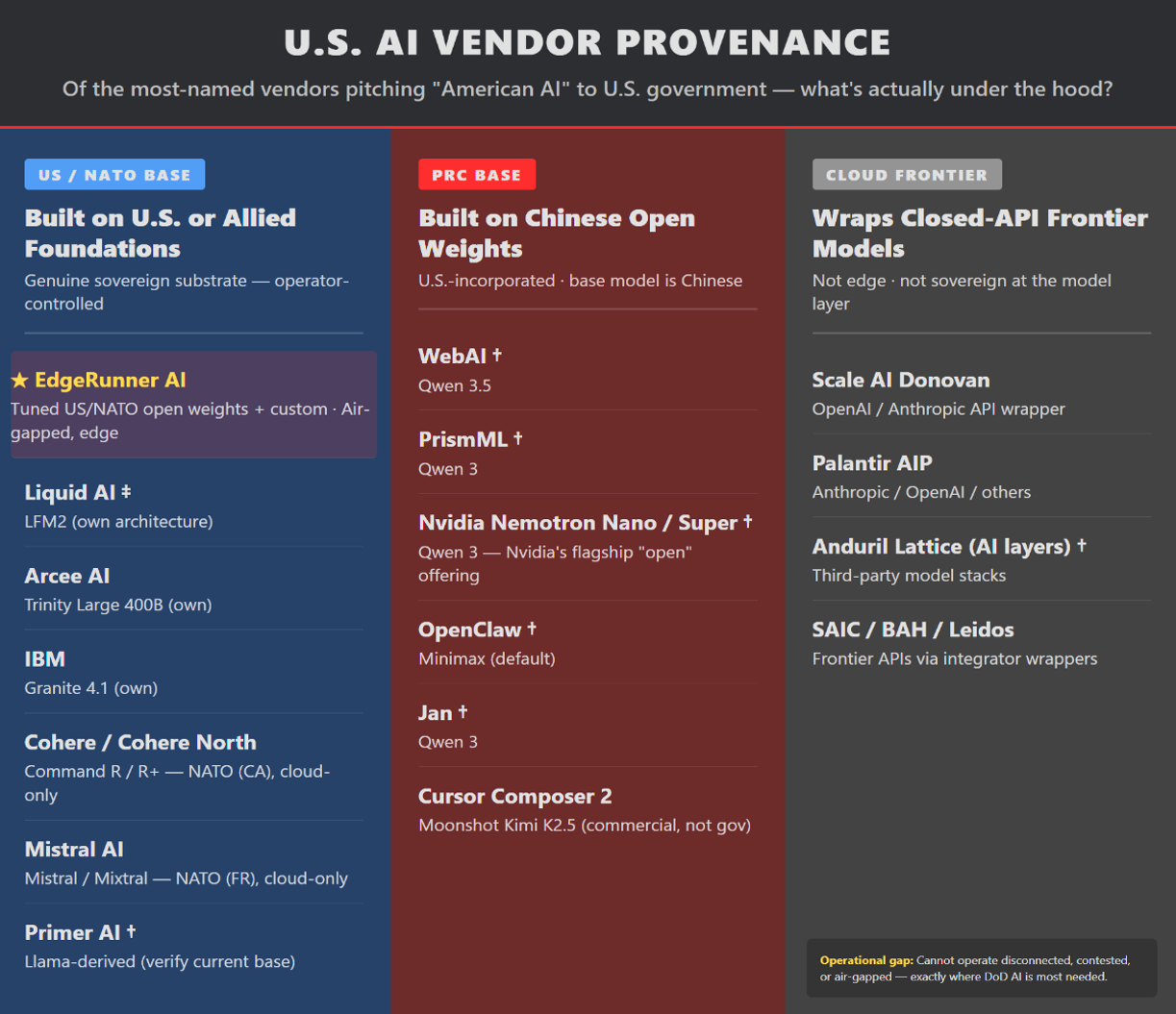
Many U.S. vendors integrating within the US Govt, DoD, & IC rely on Chinese open-weight models.
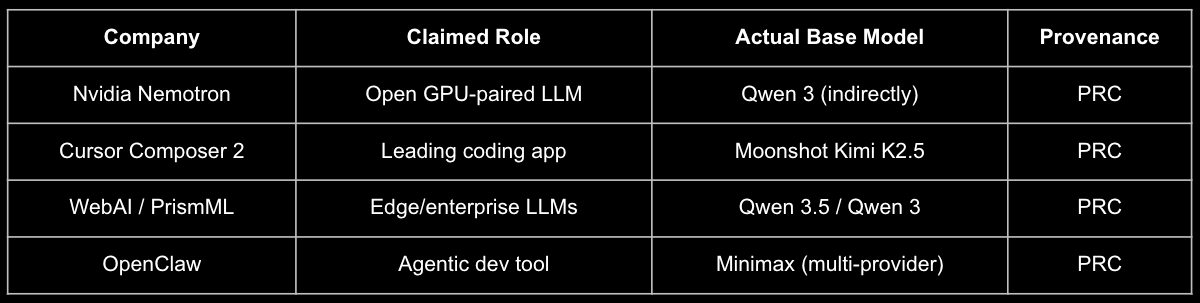
Identity contamination is already occurring: Anthropic Claude, Allen AI OLMo, and Liquid AI LFM2 have been observed identifying as Chinese models in benchmarks. Once in pre-training data, biases and vulnerabilities propagate downstream. Cloud-frontier wrappers (e.g., Palantir AIP, Scale Donovan) add value but do not solve air-gapped, contested, or edge requirements.
4. Strategic Implications
- Frontier leads last months, not years.
- Open-weight models are infrastructure, not commodities. Chinese dominance creates ecosystem lock-in, hidden biases, and architectural dependencies.
- Agentic AI runs best on open weights the operator fully controls. The gap matters most precisely where closed APIs cannot: tactical edge, sovereign IC, and disconnected operations.
5. Considerations for the Policy Makers
To close the open-weight gap and secure U.S. agentic sovereignty:
- Treat open-weight foundation models as critical infrastructure. Prioritize 70B–400B U.S.-origin bases for edge and sovereign use.
- Create targeted federal demand. Require U.S.-origin open weights for DoD/IC edge deployments to generate market signals Western labs currently lack.
- Fund open architecture R&D as a public good. Match Chinese velocity on inference efficiency, long-context, and multi-token innovations.
- Mandate provenance disclosure in federal procurement for any “American AI” product.
- Resource the full agentic stack—models, datasets, inference engines, and multi-agent frameworks—not just the model tier.
- Focus on edge AI. This is where the open-weight gap creates the most direct national-security risk.
EdgeRunner AI’s Position
EdgeRunner builds air-gapped, on-device LLMs for warfighters using tuned U.S./NATO open weights. We currently choose between less-capable U.S. bases or more-capable Chinese bases that require costly isolation and auditing. A robust U.S. open-weight ecosystem would strengthen every U.S. company, program office, and operator in contested environments.