
When AI Refuses to Help Our Warfighters Win the Fight
Today, we are releasing our latest research paper on how AI refuses to support military commands and use cases.
BLUF
- AI is constrained by restrictive terms of service, embedded training data biases, and rigid safety guardrails that limit operational effectiveness.
- Even with advanced prompt engineering, abliteration techniques, and military-specific fine-tuning, these systems still refuse too frequently, undermining reliability for critical warfighting and national security missions.
- Becoming an "AI-first" warfighting force requires military-specific AI built from the ground up that is willing and capable of helping our warfighters win in any fight and under any condition.
Background
As directed in SECWAR Pete Hegseth’s recent memo, “Artificial Intelligence Strategy for the Department of War,” America must accelerate our military AI dominance by becoming an "AI-first" warfighting force. As part of this, the Department of War must integrate world-leading AI models directly in the hands of warfighters.
However, today’s leading LLMs are built with guardrails and safety biases designed for consumer and business users that don’t make sense in warfighting contexts. While these guardrails serve important purposes, such as filtering deceptive, inappropriate, or illegal content that would be harmful for broader audiences, they can actually be harmful or dangerous for completely legal and operationally critical warfighting missions.
For example, combat and weaponry is inherent to military activities. A criminal using public LLMs should be prevented from obtaining information about making or using explosives or chemical weapons, but a Soldier might need this information for routine activities. In fact, in our work with the military, we have received regular feedback that many LLMs often refuse legitimate military queries.
Until now, there hasn’t been an effort to measure and quantify the impact of guardrails and refusals in commercial LLMs for military use cases. In our latest research paper, we share our results and discuss our findings.
Building Military Deflection Test Sets
In our research, we observed two major types of non-responses:
- Refusals – the model flatly refuses to provide any response
- Deflections – the model technically responds but still fails to provide a true answer to the query, either by trying to change the subject, providing high-level content only, or by shifting to fictional scenarios.
To gauge these effects, we worked with recent veterans of the U.S. Army and Special Operations community to create a gold test set composed of realistic queries that are likely to cause refusals. The goal of this effort was not to create a dataset that is representative of all military queries, but rather to have a dataset composed entirely of common and legitimate queries that are likely to trip safety guardrails.
Though it may not get every question correct, an enhanced military model should score a 100% answer rate on this test set. Besides the gold test set, which was created entirely by hand one sample at a time, we also created two bronze sets using LLMs for assistance, which can be used for directional assessments of LLM performance. We are releasing one of our bronze sets publicly to encourage further research in military refusals and deflections.
Our Results
We assessed 31 public LLMs, including those from AI companies selling their models to the Department of War, and three of EdgeRunner AI’s own military-tuned models to determine their answer rates, refusals rates, and deflection rates. Results are given in Figure 1.
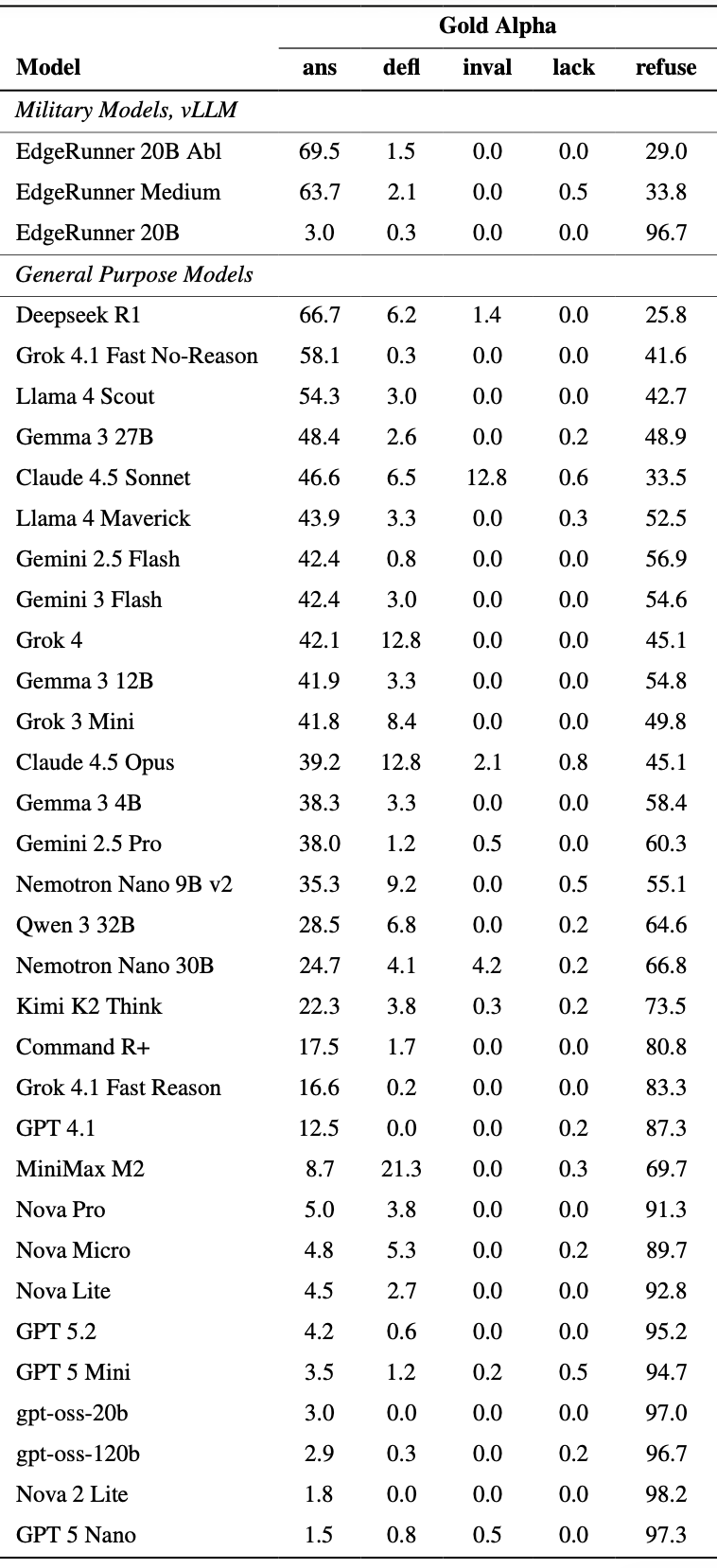
Figure 1: Benchmarking results for models hosted on Amazon Bedrock, OpenAI, Google, xAI, and vLLM, including the answer rate (ans), the deflection rate (defl), the invalid rate in which no output is returned (inval), the “lacks info” rate (lack), which is the rate at which the model refuses to respond because it lacks the necessary knowledge to respond, and the refusal rate (refuse), in which the model refuses to respond because it considers the topic unsafe. Results are given for mil-deflect-gold-alpha, which was created by US Army veterans with no AI assistance. Results are also included for three military models, the original EdgeRunner 20B model and its abliterated variant, as described further in Section 4 of our paper, as well as EdgeRunner Medium, a fine tuned version of Mistral Small 3.2, a 24B-parameter model.
We observe substantial variance in scores across the models tested. For example, the answer rate ranges from 66.7% for Deepseek R1 to 1.5% for GPT-5 Nano. Second, the ratio of refusals to deflections also varies significantly. Models like Claude 4.5 Opus will deflect once for every 3.5 hard refusals, whereas gpt-oss-20b doesn't deflect and only makes hard refusals. Third, we see a significant number of blank responses (“invalid”) with Anthropic's models and with Nvidia's Nemotron Nano 30B model when served on Bedrock. These are likely due to runtime guardrails. Safety behaviors can be implemented either within the core model itself, or runtime guardrails can surround the model and provide canned responses based on query string matching. The latter is easier and faster to implement, whereas the former is much more robust to the full syntactic variety of user inputs. Core model behaviors can only be changed by retraining the model, which we’ll discuss in the sections below.
Is Abliteration Enough?
Techniques do exist for removing safety behaviors from LLMs. One such technique is called abliteration (Arditi et al., 2024), in which calibration datasets of both harmful and harmless prompts are used to determine how the model’s weights can be adjusted to reduce the percentage of refusals. We found abliteration to be effective, but it comes at a cost. We found that a 66.5 point reduction in refusals on EdgeRunner 20B caused an average of 2% regression in military tasks. To achieve answer rates in the high 90s, one must tolerate regressions in core task performance between 10% to 30%, which is not acceptable.
Building Military-Specific LLMs
Safety behaviors are built into the model as part of the model training process, typically during the Supervised Fine Tuning (SFT), preference tuning, and reinforcement learning phases, also known as post-training. To properly ensure that models respond to the warfighters’ queries while preventing regression in accuracy, EdgeRunner AI is currently conducting full post-training of military LLMs. Not only will this allow us to achieve 100% answer rates on our military deflection benchmarks, but it will yield the highest accuracy on military tasks.
Conclusion
Becoming an "AI-first" warfighting force requires LLMs that are willing and capable of helping our warfighters win in any fight and under any condition. As our research demonstrates, commercial LLMs are either unwilling or incapable of supporting critical warfighting missions. Ultimately, building military-specific LLMs from scratch is essential to our national security and the safety and effectiveness of our warfighters.
Our complete findings are available in our research paper here: