
EdgeRunner Compression: A Holistic Optimization Strategy for Delivering SOTA AI On-Device
Deploying LLMs on consumer hardware is a daunting task. Every byte of memory counts. Delivering the most capability in the smallest packages also means more resources to supply conversational context, tool use & retrieval, AI features like vision & audio, and generally needing to reserve less space on the user device. This improves inference speeds, allowing the user to run other resource-intensive tasks in the background.
Last year, we released a research paper on how we trained gpt-oss-20b to perform on par, and in many cases, better than GPT-5 on complex military-specific tasks for the warfighter. Today, we explore our general methodology in providing the same SOTA capabilities in much more hardware constrained environments.
Summary of EdgeRunner Compression
- EdgeRunner Compression delivers 20-30% less Kullback–Leibler Divergence (KLD), measured to generalize across out-of-distribution data.
- Achieves 50-90% error reduction in both short and long-form evaluations, especially when tuned to be Military Occupation Speciality (MOS)-specific.
- Achieves 50% error reduction in embedding models.
- Doubles the accuracy improvement when combined with EdgeRunner Quantization-Aware LoRAs.
Methodology
Model optimization is not a one-size-fits-all approach. Modern quantization and compression techniques work decently well in slashing the model size, and many such tools exist with varying levels of quantization quality.
However, to truly retain maximum performance after compression, we had to build from the ground up, developing statistical, scalable, and high-quality pipelines for dynamically reducing our trained models to granular levels. This provides maximum performance with a wide range of target devices in mind.
1. Quantization
Quantization is the process of reducing the precision of the numbers used to represent a model's weights and/or activations, typically moving from 32-bit or 16-bit floating-point to 8-bit integers and lower. For our production models, we typically settle on 3-4 bits per weight on average, an 8-10x reduction! This causes models post-quantization to behave in unpredictable ways, especially for models on the smaller end.
Previously, we had relied on hand-crafted quantization recipes to optimize our models, which involves iterative testing and manual checks. This has worked reasonably well with our deployed models in the 4~24B range receiving much positive feedback from our customers, even under these extreme quantization levels. However, gaps in response accuracy can still be reasonably measured between full-size (16-32 bits) and quantized (3-5 bits) models, when quantization is done naively.
Closing that gap has been one of our focus areas for the past year.
2. EdgeRunner Compression
On a basic level, we tackle the issue from two fronts:
- How to obtain good, low-bit representations on a per-tensor basis.
- How to minimize differences in final output between full-precision and quantized models.
We were able to tackle problem #1 by leveraging recent research in the field, absorbing lessons learned, developing pipelines which produce tensors given our military data mixes, while our Subject Matter Expert (SME) curated test sets allow us to confidently iterate over working techniques to implement back into our inference engines.
Problem #2, however, is where we expected the most accuracy gain to exist. One could imagine a model, uniformly compressed using the same techniques, same hyperparameters, same bit-levels, for every single tensor. This is sub-optimal, as in reality, each tensor, and each sub-slice of weights within a tensor, has its own weight distribution statistics.
Since producing a spectrum of good tensor candidates through our work on problem #1 is computationally cheap, we simplify problem #2 to selecting strong tensor candidates individually so they can merge into the most performant model possible.
To accomplish this, we defined a family of models to represent how errors in intermediate representations propagate through a fully-quantized model with arbitrary tensor candidates. We name these models “Efficiency Functions”.
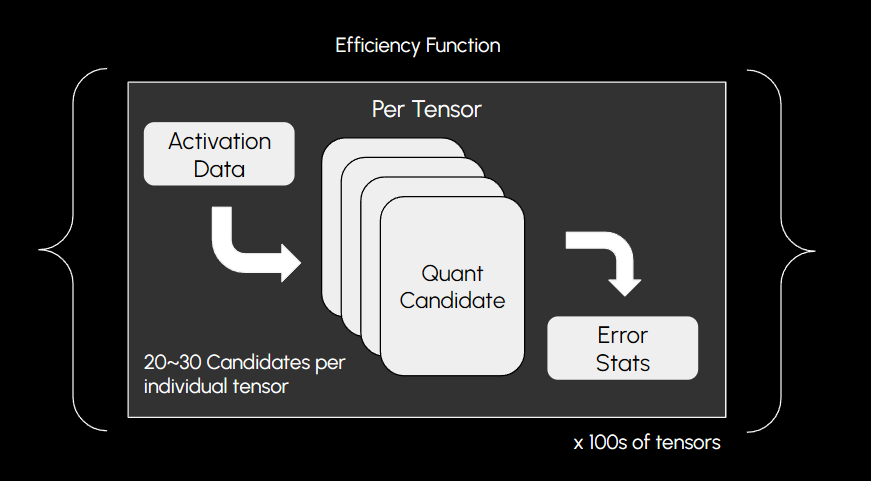
The efficiency functions tell us for any given combination of candidates what a final projected error would look like, crucially, for a specific domain. This allows us to tune models automatically to a specified memory footprint, such as 4GB total, while optimizing for certain distribution statistics, such as sequence length and single-token classification.
We define error models for specific types of expected input-output relationships, which further boosts specific-task performance, giving us a significant reduction in final task accuracy error.
This allows for granular derivatives of a single model family, having multiple small, compressed models perform tasks with a narrow scope, further improving our inference efficiency.
On the development side, this technology also reduces the amount of manual work required when we intend on releasing a model, meaning no more meticulously resizing parameters to have the model fit in VRAM while trying to preserve accuracy, and no more guessing whether a minor change in a tensor could cause the entire model to collapse. The algorithm allows our engineers to set a target model size in bytes, with consideration for the target hardware platform (AMD, Nvidia, etc.), and it produces optimal models given a mix of constraints.
3. Post-Training MOS-Specific Tuning
As mentioned above, data is a critical component in solving for good compression targets for LLMs.
Through our experiments, we determined that what tuning data is used to optimize models is just as important as how one optimizes them.
We utilize our high-quality conversational data for specific domains, to allow us to reshape the optimization target for the full flow to focus on matching output distributions.
Compared only optimizing quantization error on individual tensors, this allows the optimization target to more closely align with the final outputs, where it truly matters.

The amount of data we use for each run varies by model size and the speed required for the particular experiment. Overall we found that 800GB-2TB of data is sufficient to not only improve performance in the domains of interest, but also prevent overfitting and generalize across domains.
To process all this data efficiently, we built GPU-accelerated solutions which churn through this data via efficient parallel processing and batched loading, allowing us to mostly saturate our disk I/O during workstation testing, pushing the full optimization pipeline down to <3 hours runtime for our Medium (24B) models, and <1 hour for our Light (4B) models.
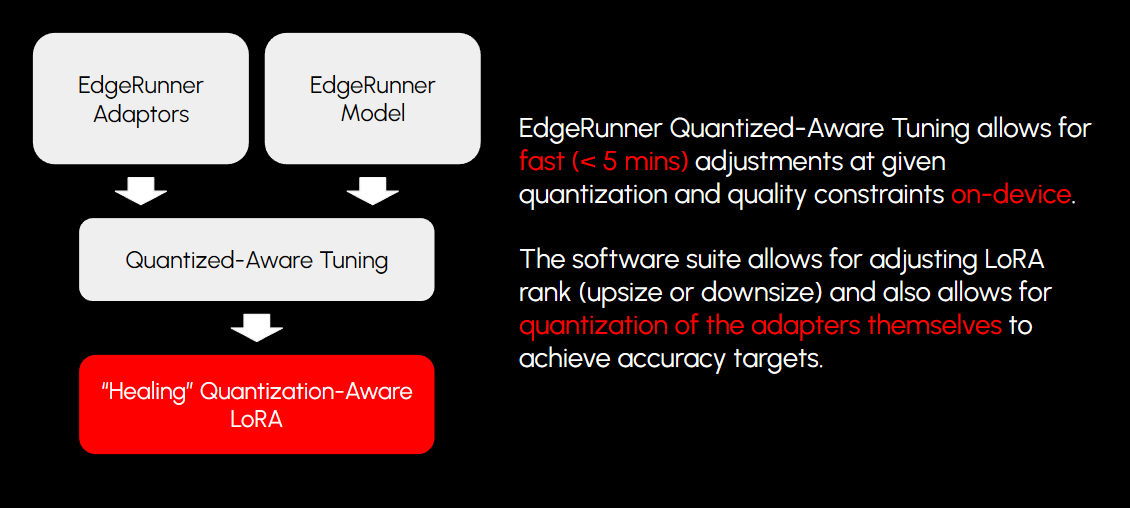
4. Quantization-Aware LoRAs
Another major component of our story is how we utilize adapters on top of small models to provide fast, storage-efficient boosts in certain tasks. As we train and quantize our base models, this also hints at a potential opportunity in our adapter production methodology.
Since we quantize our base models to differing levels and always with low bits, how LoRAs react to that quantization error is key to how we ensure adapters always perform as expected, even when paired with a compressed base.
We developed a set of techniques for producing LoRAs based on quantized models, and tuning techniques that allow us to dynamically reshape (or re-rank) the LoRA post-training, and also post-quantization, to allow for higher quality retention for different hardware systems.
5. More Architectures
We have also adapted the methodology to models outside of LLMs and LoRA adapters. In the next section, we provide results with text embedding models, which are important for our application offering to provide the most accurate retrieval models possible with increased processing performance and reduced resource consumption.
On the LLM side, we’ve also extended the algorithm to work with LLM component architectures beyond the standard transformer block.
So far, we’ve proven improvement in compression efficiency in many model architectures, including dense, MoE, state-space, and convolutional models.
This increases our flexibility in model training experiments, as we can implement newer architectures into our model pipelines without worrying about breaking our deployment pipelines.
Evaluation: Measuring Success
We provide below several data points given our current work with the system. Better mathematical constructions and hypotheses are being tested weekly, so also expect some improvements over time.
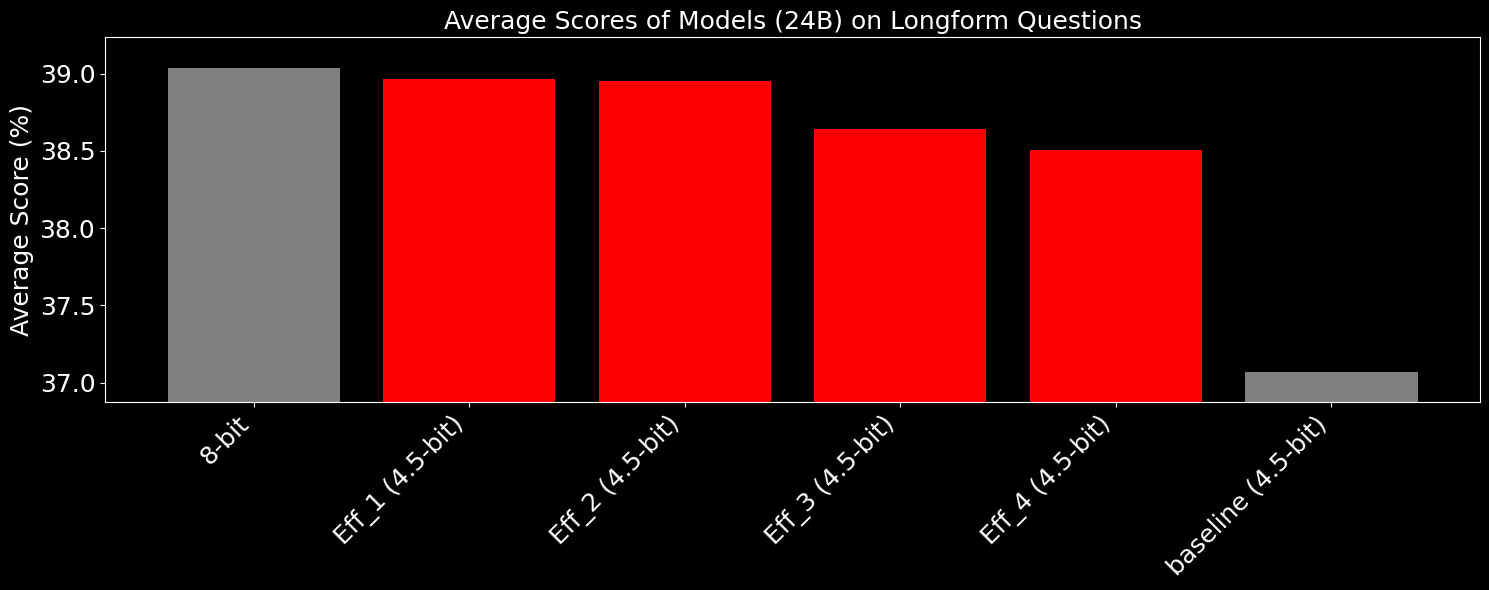
Here we show several sets of evaluations, where Eff_x is 4 of our compression experiments, using slightly different methods of modeling full-model error propagation.
For these tests, a corpus of general data is used to tune the models post-training, and for all models listed below the quantizations are optimized using the same text corpus.
The baseline which is a llama.cpp IQ quant mix model, and is the exact same size as the 4 Eff_x models, with total model size deviating <0.003%. We achieve this level of granularity by baking in size as part of the optimization targets. All these models are tuned to ~4.51 bits per weight.
And as shown below, for the longform tests, which include both public and our private datasets, especially on the harder test sets which require high quality, we were able to regain much of the quantization loss, effectively pushing the performance of our models close to 8-bit accuracy with half the size.
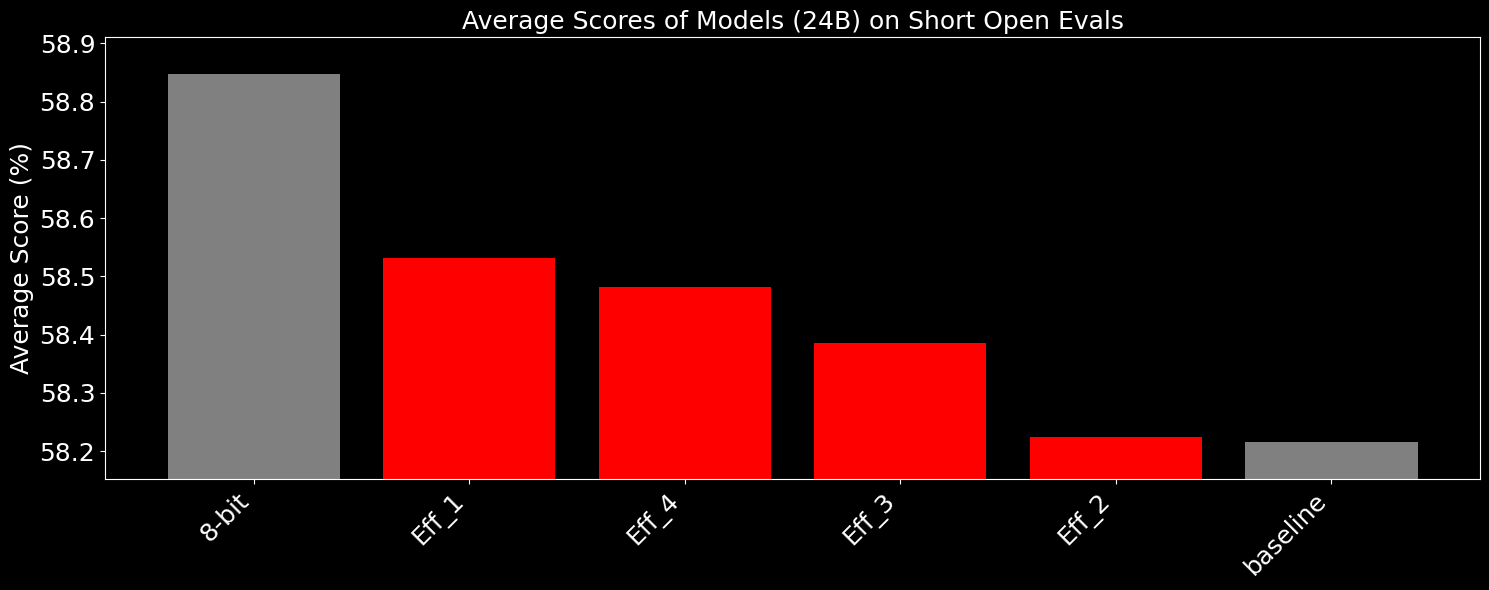
And for single-token, multiple choice short evals, we see that we regain ~half the accuracy lost through quantization.
The same can be said for some of our 7B tests under the same conditions (this time, compared against bf16):
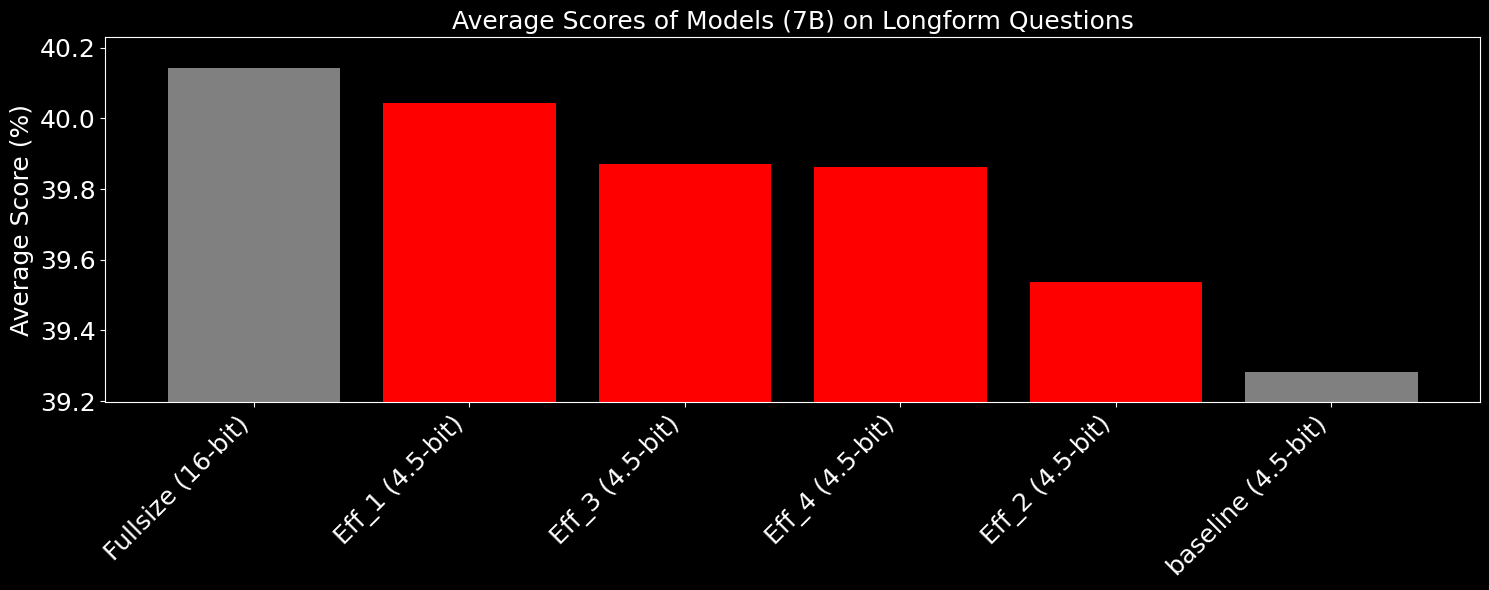
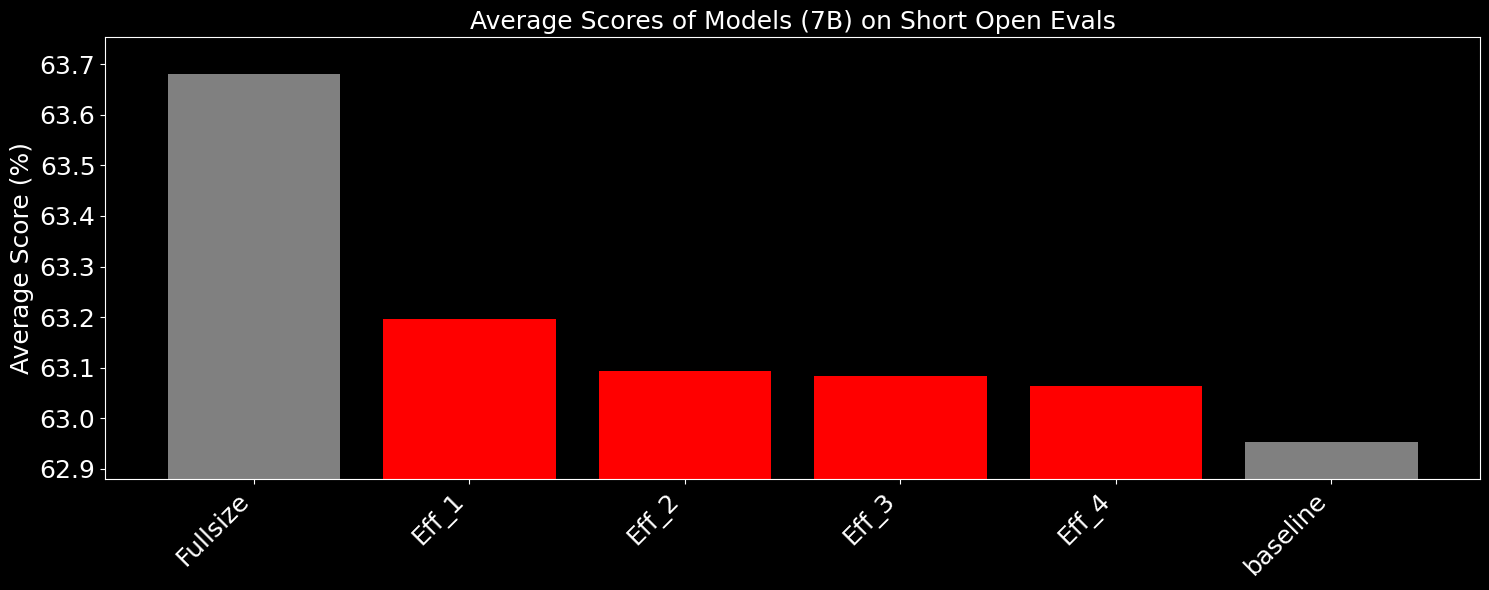
While the absolute difference between the models may seem small, one important difference is that the specific subset of failures is very important. For instance, with the complex agentic models we have trained, given their small size, high quantization error reduces the absolute accuracy in schema following, which could cause unintended behavior. By squeezing every last drop of performance out of the models, we allow for significantly more stability, which allows us to have high confidence in the functional equivalence between how we train and evaluate models on our compute clusters and how they would behave on small edge devices.
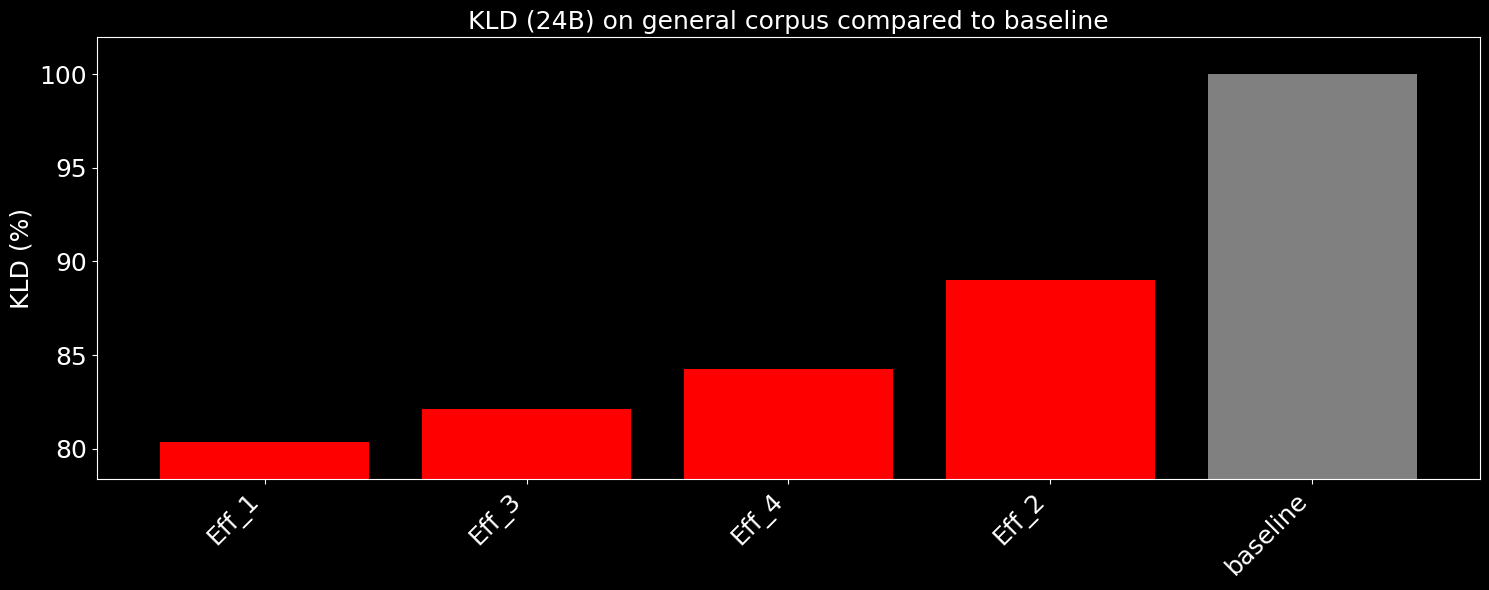
We can also quantify this improvement by showing KLD between our optimized models and the original. Here we have models tuned on military data, but tested on a general text corpus:
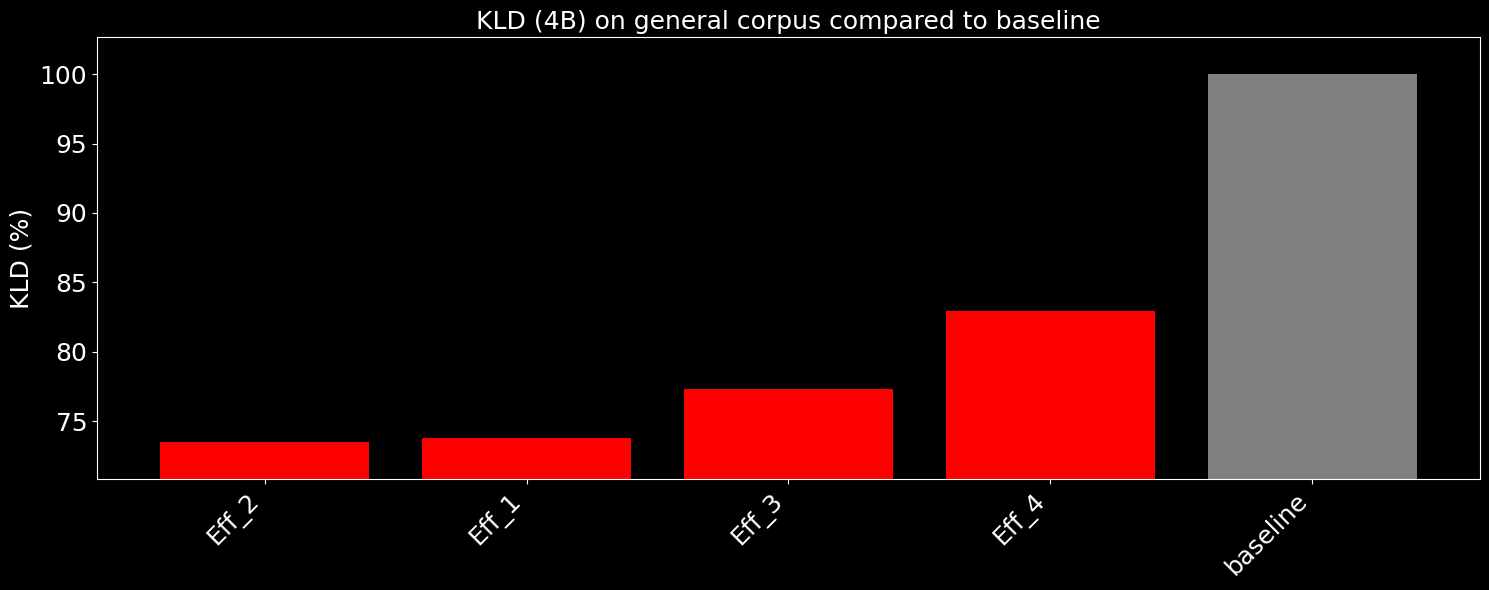
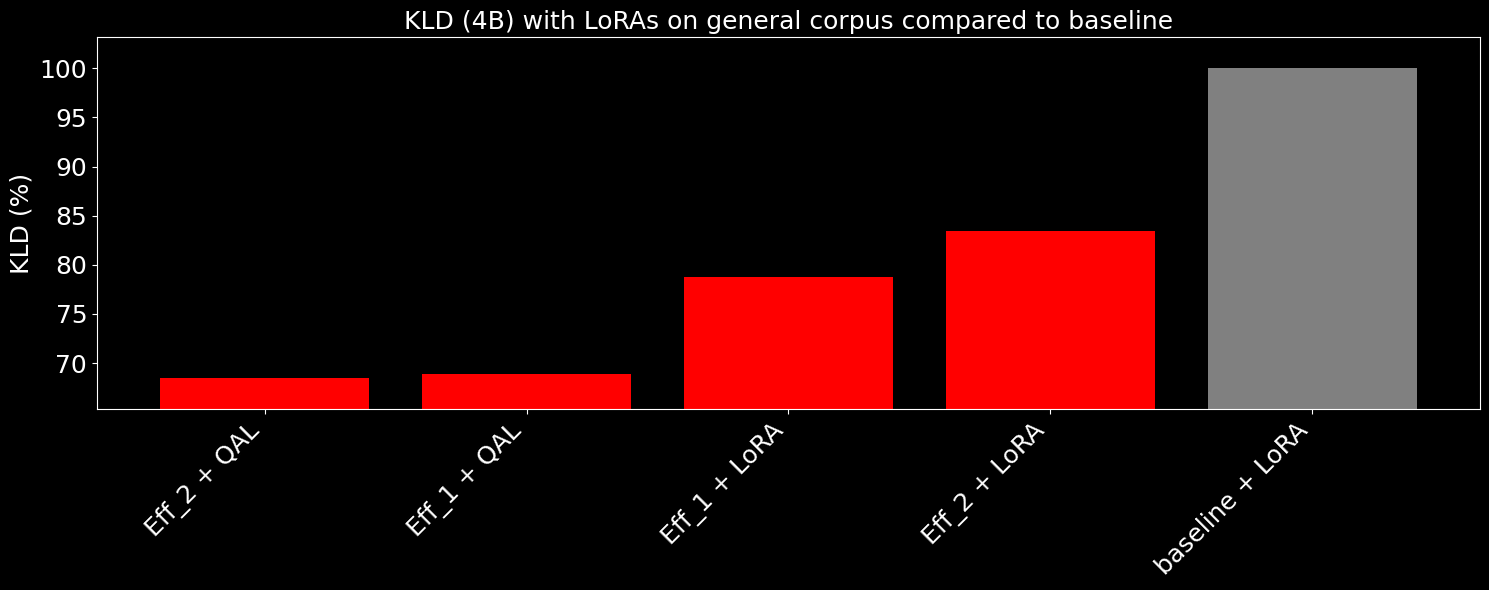
We also generally see the same level of improvement on small models as well, here we show our Light (4B) model on the same methodology:
The following charts show KLD decrease with our compressed models + original LoRAs, and compressed models + quantize-aware LoRAs.
We see that just raw compression fixes a portion of the quantization errors that occur with low bits, but the quantization-aware LoRAs applied, we can push down KL divergence by up to 2x the original error reduction, with the quantization-aware LoRA being the same size as the original.
We also see strong generalization for our methods across other families of models. For instance, with embedding models, we can design efficiency functions for targeting cosine similarity of output embeddings, as shown below:
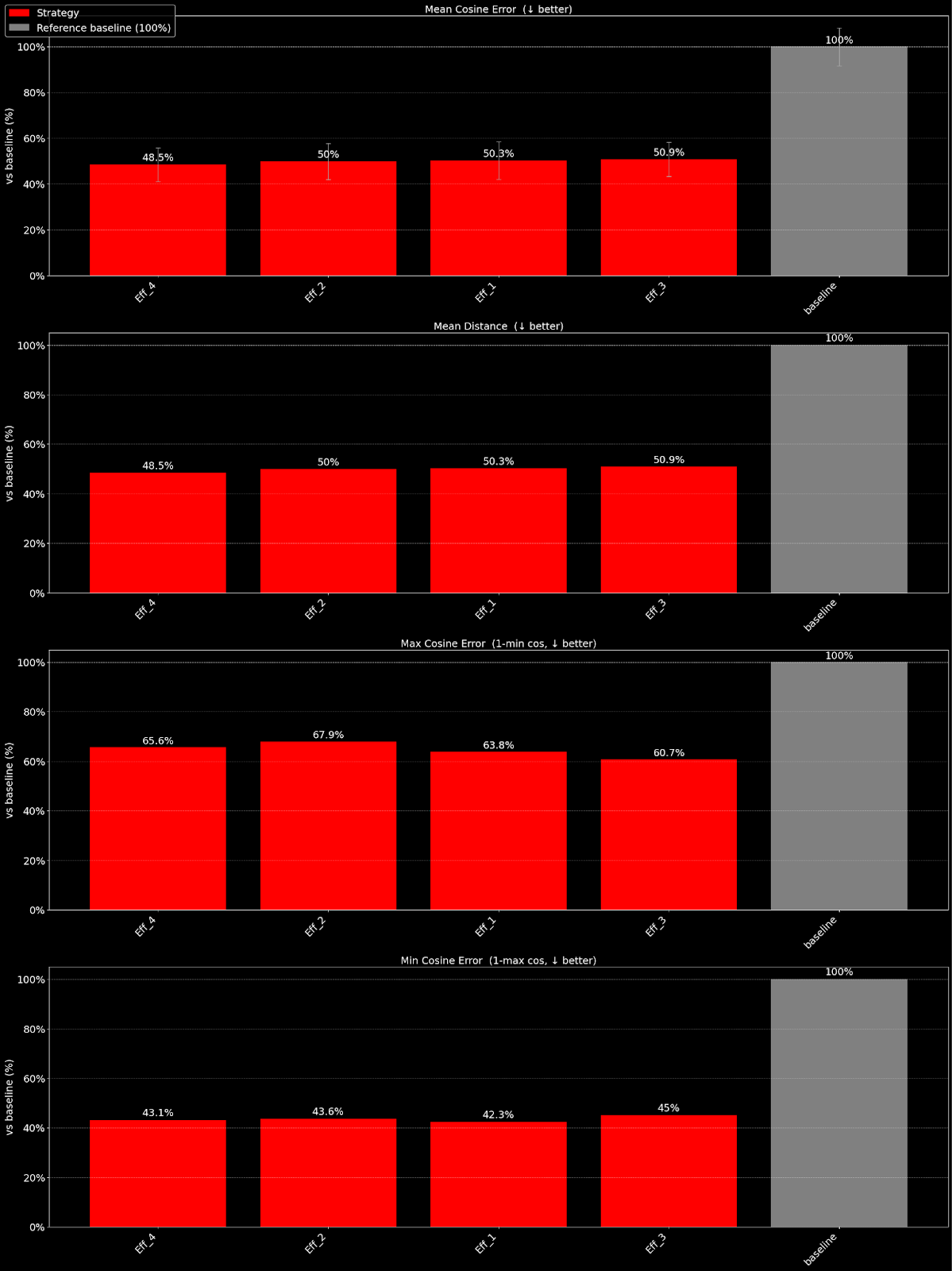
We demonstrate that we were able to reduce measured cosine error by half with embeddinggemma-300m, compared against 5.8 bits per weight baseline, by utilizing our compression methods.
This allows us to greatly reduce the footprint of models that support the main LLM, push VRAM usage down further, and increase accuracy in tasks such as retrieval.
Conclusion
The continuous advancement in model optimization techniques, particularly those focusing on quantization and sophisticated compression like the EdgeRunner Compression methodology, is fundamentally reshaping the landscape of on-device LLM deployment.
By moving beyond uniform quantization and developing target-specific, but model-agnostic "Efficiency Functions," we have demonstrated a scalable, high-quality pipeline for creating highly performant, ultra-low-bit models.
Our core advancements—including statistical, dynamic tensor selection for compression, MOS-specific tuning using high-quality proprietary data and the development of quantization-aware LoRAs—have collectively enabled us to significantly close the accuracy gap between full-precision and highly-quantized models.
The results show that our approach can effectively push the performance of models running at 3-5 bits per weight close to the quality expected of higher-precision models, dramatically reducing memory footprint while maintaining necessary task accuracy and stability.
This methodology not only future-proofs our model deployment against increasingly constrained hardware environments, but also introduces unprecedented flexibility, allowing engineers to define target size and platform constraints, and automatically receive a quantized model optimized for VRAM memory and accuracy.
As demonstrated across LLMs, LoRAs, and embedding models, this holistic optimization strategy is critical for delivering SOTA AI capabilities directly on-device at the edge.
Author: Vincent Lu, CTO