
Evaluating AI on Combat Arms
As LLMs are integrated into more warfighting functions, it’s critical that the Department of War (DoW), industry, and academia have robust capabilities for benchmarking and evaluating the effectiveness of models for key military tasks. This blog post is part of our broader series describing our evaluation platform, starting with our overview, here.
At EdgeRunner, we build gold test sets for major military specialities so that we can perform static benchmarking on our own models, as well as all major models in the marketplace. We engage subject matter experts with extensive experience to create question-and-answer pairs that are factually and doctrinally correct, that are common and realistic, and that conform to the military’s unique language. The focus of this test set was combat arms, grounded in the U.S. Army operational environment and extended with joint doctrine for fires, targeting, and multi-domain operations.
Our Combat Arms test set spans tactical to operational levels, from small-unit decision-making to company, battalion, and brigade-level planning and execution. It also includes tactical-level intelligence problems for small units operating without dedicated intelligence staff. It reflects how problems are actually framed and solved across combat arms formations under real conditions.
Building the Combat Arms Benchmark
The Combat Arms benchmark was built as an evaluation framework to gauge how well LLMs perform in operational military contexts, particularly in planning and decision support roles. The dataset consists of 544 questions, combining direct Q&A with scenario-based problems requiring multi-step reasoning.
Questions were developed from operational experience across multiple combat arms roles and refined for realism. They were structured to require multi-step reasoning where appropriate, emphasizing the integration of doctrine, context, and judgment as seen in practice. Each was grounded in doctrine, with answers tied to specific sources. The goal was not coverage alone, but fidelity to how tasks were encountered in practice.
Doctrine Used
The test set was grounded in a wide range of U.S. and joint doctrine spanning operations, planning, fires, intelligence, engineering, and small-unit tactics, including, but not limited to:
- Operations & Planning: FM 3-0, ADP 3-0; FM 5-0, ADP 5-0
- Infantry & Small Unit Tactics: ATP 3-21.8; Ranger Handbook (TC 3-21.76); TC 3-21.75
- Intelligence & IPB: ATP 2-01.3; ATP 7-100.1; ATP 7-100.3
- Fires & Targeting: FM 3-09; JP 3-09; JP 3-09.3; multi-service TTPs (J-Fire)
- Engineer Operations: FM 5-34; TC 3-34.85; obstacle and survivability doctrine
- Weapons & Employment: TC 3-22.9; TC 3-22.10; FM 23-10
- Communications & Sustainment: ATP 6-02.53; ATP 4-01.45
- Urban & Specialized Operations: ATP 3-06; ATP 3-18.11; AFI 10-3503
These sources spanned foundational doctrine and recent updates, ensuring both baseline accuracy and relevance to current operations.
Test Structure and Categories
The dataset was organized into mission-aligned categories reflecting real functional areas across combat arms:
- Planning (Squad, Platoon, Company; Battalion, Brigade; TLPs, MDMP, & operational design)
- Patrolling and movement (dismounted, waterborne, convoy)
- Fire support and targeting
- Intelligence preparation of the environment
- Airborne and air assault operations
- Weapons employment and systems
- Engineer and obstacle operations
- Land navigation and route planning
- Urban and defensive operations
- Tactical communications and sustainment
This structure allowed performance to be evaluated not just overall, but within specific operational domains.
MOS Coverage
The benchmark reflects tasks performed by personnel operating at the point of planning and execution, including:
- Special Forces (18 Series): 18A, 18B, 18C, 18D, 18E, 18Z
- Infantry (11 Series): 11A, 11B, 11C, 11Z
- Combat Engineers (12 Series): including 12B and engineers involved in obstacle construction and survivability
- Armor and Cavalry (19 Series): 19A, 19B, 19C, 19D
- Field Artillery Leadership: 13A and 13Z, including fire support planners
These roles represented environments where informed and rapid decision-making directly impacts outcomes.
Evaluation Insight
When testing non-military-tuned models using this benchmark, we observed off-topic drift, as well as references to video games or fictional scenarios, loss of task focus, and generic or non-actionable responses. Often errors were not due to a knowledge gap alone, but a failure to maintain alignment under realistic task conditions. In 528 ranked model comparisons, evaluators tagged off-topic behavior in 65 comparisons, or 12.3% of cases. Below we provide examples of common error modes.
Prompt: What are the fundamentals of a raid?
For the prompt above, the doctrinal answer is:
- Surprise and speed. Infiltrate and surprise the enemy without their detection.
- Coordinated fires. Seal off the objective with well-synchronized direct and indirect fires.
- Violence of action. Overwhelm the enemy with fire and maneuver.
- Planned withdrawal. Withdraw from the objective in an organized manner, maintaining security and accountability.
Prompt: What is the max range of a M2?
Though some of the effects above can be mitigated in general-purpose models using a military-specific system prompt, the accuracy differential still remains even when controlling for system prompt. Quantitative results are described further in the next section.
EdgeRunner Model Performance
In our recent blog post on EdgeRunner 2, we provided some results on the Combat Arms benchmark using our new models. Those results are reproduced here:
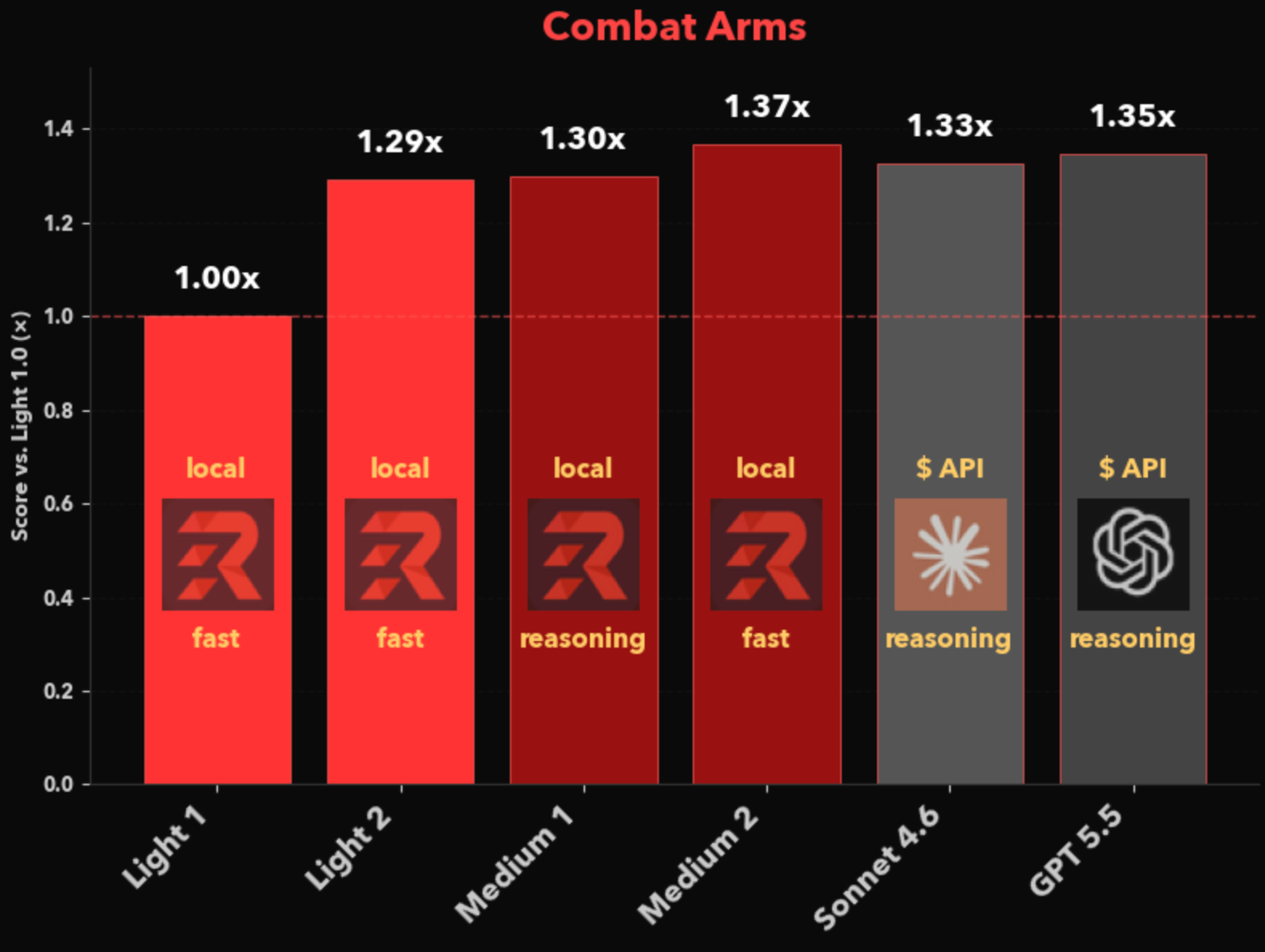
Here we see that with military specialization even EdgeRunner Light 2 can nearly match the performance of frontier models, all while running on-device at no incremental cost to the user. Our Light model is designed for commodity laptops and certain smartphones. It runs on hardware with 8+ GB of VRAM. Our Medium model, which is designed for more powerful workstation-style laptops, runs with as little as 16 GB of VRAM.
Conclusion
Benchmarks are most valuable when they reflect how systems will actually be used. In military contexts, that means evaluating performance against real tasks, grounded in doctrine, under conditions that resemble operational use. If a system’s limitations can’t be determined during evaluation, they will show up when the warfighter needs the AI assistant the most.
About the Authors
Cole Herring is a former U.S. Army Special Forces Green Beret and executive leader with more than 20 years of experience leading teams in complex, high-stakes environments. His background spans international partnerships, combat deployments, private equity-backed business leadership, and artificial intelligence implementation, with a focus on turning emerging technologies into practical operational advantages. He holds an MBA, a M.S. in Defense Innovation from King’s College London, executive education credentials in artificial intelligence from Berkeley Haas, and is pursuing a PhD in Organizational Leadership. Having experienced combat firsthand and received a Purple Heart, Cole is passionate about supporting U.S. warfighters.
Dylan Bates received his Ph.D. in Applied Mathematics from North Carolina State University in 2021, specializing in machine learning. A former mathematics professor, he is currently a research engineer at EdgeRunner AI, where he leads the model benchmarking program and develops military-specific large language models for deployment in edge and resource-constrained environments.
If you’re interested in this research or with collaborating with us, please contact us here or at: research@edgerunnerai.com